Export CSV
지난 주 회사에서 CSV 형태로 친구목록을 내보내는 API를 추가하는 작업이 있었습니다.
작업 내용은 아래와 같습니다.
- Response Header를 명시한다. -> (Content-type: application/csv)
- List를 하나 생성한다.
- List에 CSV의 헤더(첫 행)을 삽입한다.
- 친구 목록 테이블이 5개의 다른 테이블과 LEFT JOIN해서 결과를 받는다.
- 조회 결과를 record 단위로 순회하면서 CSV에 맞는 스펙으로 변환하고 List에 삽입한다.
- 결과를 반환한다.
중요한 점은 개발해야 하는 CSV 구조 <-> Tables 구조가 많이 달라서 데이터 가공 작업을 했어야 했습니다.
예를 들면, 아래와 같은 CSV 스펙이 필요하다고 가정합시다.
| 집 주소 | 회사 주소 | 배송 주소 | 팩스 주소 | 기타 주소 |
Table 구조는 이렇게 생겼습니다.
| address | type |
그 결과 Address 테이블을 조회해서 type 컬럼에 따라, CSV의 몇 번째 열에 넣어야 하는 지가 정해져야 했습니다.
즉, 데이터 가공이 너무 많이 일어났습니다.
그래서 성능상 이슈가 없는지, 반드시 확인해야 했습니다.
부하 테스트
부하 테스트를 위해 Rancher(Kubernetes 관리 툴)을 사용했습니다.
DB에 Dump data를 100,000 rows를 추가했습니다.
그리고 API에 1번 요청을 보냈고 결과는 아래와 같습니다.
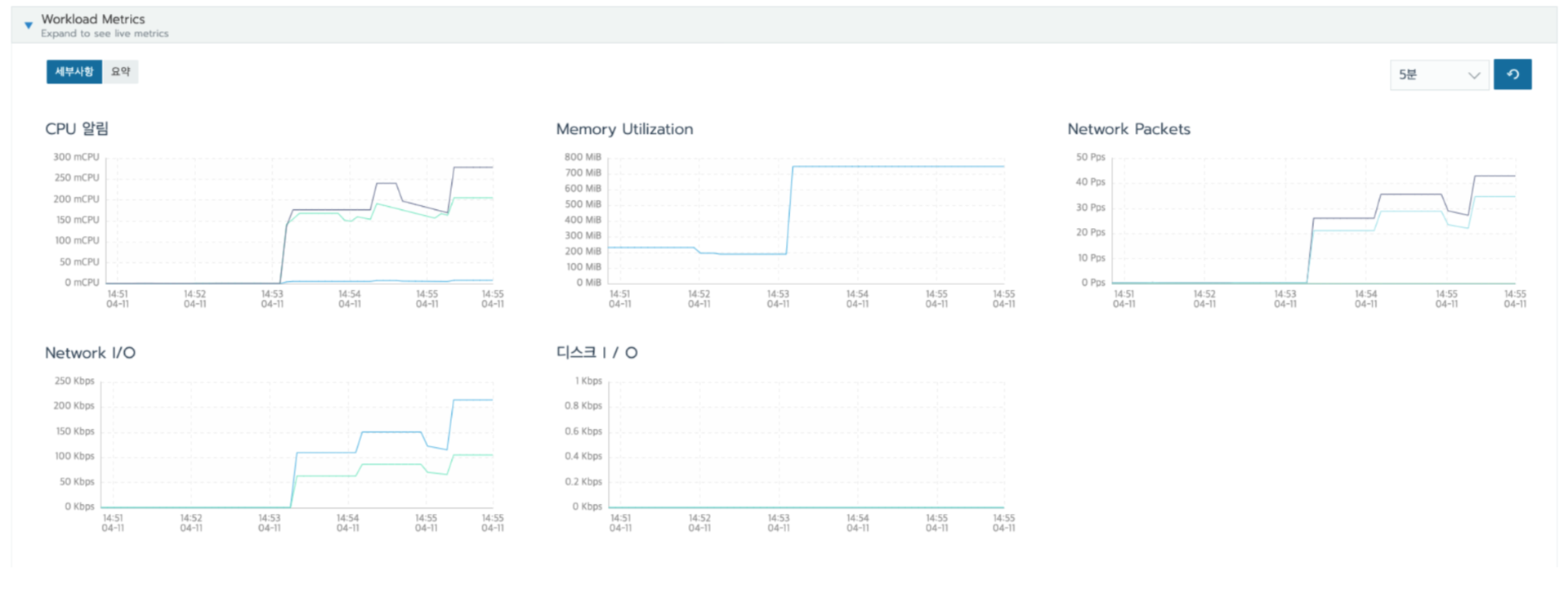
처리 시간은 15초 정도 소요되었고, CPU나 네트워크 부하는 큰 문제가 없었는데, 1건의 요청에 메모리가 500M 정도가 튀었습니다.
브라우저 Tab 3개를 열어서 동시에 요청 보내니 메모리 점유율이 2기가 가까이 올라갔습니다.
메모리가 저렇게 튀어버리면 Memory Leak가 성능 저하가 이루어질 수 있습니다. OOM(Out of Memory)으로 운영 중인 앱이 종료될 수도 있습니다.
Chunk 적용
Memory가 튀는 이유는 데이터 가공 과정이었습니다.
100,000건의 데이터를 한 번에 조회해서 메모리를 점유하고 있고, 한 번에 정렬하고 가공해서 처리할려고 하니까 메모리가 많이 쌓였던 것 같습니다.
ORM 프레임워크가 지원하는 Chunk를 사용하면, 쿼리문을 더 작은 단위로 보내고 더 작은 단위에서 데이터를 가공할 수 있습니다.
그래서 Chunk를 사용하고 size=3000을 사용했습니다.
다시 동일한 API에 2개의 요청을 보낸 결과입니다.

이전과 비교했을 때 메모리 사용률이 현저히 감소한 것을 볼 수 있습니다.

감사합니다.
'Operation > Network' 카테고리의 다른 글
| CORS 총정리!! (+ Cannot use wildcard in Access-Control-Allow-Origin when credentials flag is true 해결) (0) | 2022.04.22 |
|---|---|
| DNS round robin 방식 장/단점과 해결방안! (0) | 2022.04.21 |
| HTTP - 청크 인코딩(Transfer-encoding: chunked) [Size가 큰 테이블, 이미지 등 내려주기] (0) | 2022.03.28 |
| 메일 서비스 작동 원리 (with 구글, 네이버 등) (0) | 2022.03.05 |
| Docker Apache에 HTTPS(SSL) 적용하기 [+HTTP, HTTPS 간 쿠키 전송안될 때] (0) | 2022.03.02 |