LIMIT
Limit 절은 쿼리 결과에서 지정된 순서에 위치한 레코드만 가져오고자 할 때 사용한다. 아래의 예제를 보자.
SELECT * FROM employees
WHERE emp_no BETWEEN 10001 AND 10010
ORDER BY first_name
LIMIT 0, 5;위의 쿼리는 다음과 같은 순서로 실행된다.
- employees 테이블에서 WHERE 절의 검색 조건에 일치하는 레코드를 전부 읽어 온다.
- 1번에서 읽어온 레코드를 first_name 칼럼값에 따라 정렬한다.
- 상위 5건이 정렬이 완료되면 즉시 쿼리를 멈춘다.
- 정렬된 결과의 상위 5건만 사용자에게 반환한다.
Oracle의 ROWNUM과 달리 MySQL의 LIMIT은 항상 쿼리의 마지막에 실행된다. 즉, 데이터 전체를 조회해서 메모리에 저장한 후에 LIMIT으로 실제 사용할 데이터만 추출하고 나머지 데이터는 버리게 된다.
예시를 살펴보자.
SELECT * FROM employees LIMIT 0, 10;- 풀 테이블 스캔을 실행하면서 10개의 레코드가 되는 순간 쿼리를 멈춘다.
- 즉, 정렬이나 그룹핑, DISTINCT가 없는 쿼리는 LIMIT절을 사용하면 쿼리가 빨리 종료되어 성능이 향상된다.
SELECT * FROM employees GROUP BY first_name LIMIT 0, 10;- GROUP BY 가 처리되고 나서야 LIMIT 처리를 수행할 수 있다.
- 즉, LIMIT 절이 있더라도 실질적인 서버의 작업 내용을 크게 줄여주지는 못한다.
SELECT DISTINCT first_name FROM employees LIMIT 0, 10;- 중복 제거 작업(임시 테이블 사용)을 진행하다가 10건이 완료되면 즉시 쿼리를 멈춘다.
- DISTINCT와 함께 사용된 LIMIT은 실질적인 중복 제거 작업의 범위를 줄이는 역할을 한다.
SELECT * FROM employees WHERE emp_no BETWEEN 10001 AND 10010
ORDER BY first_name
LIMIT 0, 10- 정렬이 10건이 완성되는 순간 즉시 쿼리를 멈춘다.
- 정렬을 수행하기 전에 WHERE 조건에 일치하는 모든 레코드를 읽어 와야한다.
- 즉, 이 경우도 작업량을 크게 줄여줄 수 없다.
No Offset
LIMIT을 사용할 때 한 가지 더 주의해야 할 것이 있다. LIMIT 절의 OFFSET이 클 경우 성능에 큰 문제를 일으킬 수 있다. 아래의 경우를 보자.
SELECT * FROM salaries ORDER BY salary LIMIT 0,10;
-- 10 rows in set (0.00 sec)
SELECT * FROM salaries ORDER BY salary LIMIT 2000000,10;
-- 10 rows in set (1.57 sec)두 쿼리는 동일하게 10건을 반환하지만 두 번째 쿼리는 실행 시간이 100배 이상 많이 걸렸다. 그 이유는 두 번째 쿼리의 경우 2000010건의 레코드를 읽은 후 처음 2000000건은 버리고 마지막 10건을 반환하도록 동작하기 때문이다.
즉, 두 쿼리는 실제 사용자의 화면에는 10건만 표시되지만 두 번째 쿼리는 훨씬 더 많은 레코드를 읽어야 하기 때문에 쿼리가 느려지는 것이다.
이때는 Offset 대신에 이전 페이지 조회 결과 중 마지막 salary 값과 emp_no 값을 사용하는 No Offset 방식으로 조회하는 것이 좋다. 가령, 두 번째 페이지를 조회하게 된다면 아래와 같은 SQL 문을 사용하게 된다.
SELECT * FROM salaries
WHERE salary < 38864
ORDER BY salary DESC
LIMIT 10;
-- 10 rows in set (0.00 sec)결과적으로 LIMIT의 Offset이 아닌 WHERE 절로 조회 범위를 제한함으로써 아무리 페이지가 뒤로 가더라도 처음 페이지를 읽은 것과 동일한 성능을 가지게 된다.
Why ?
포스팅을 하다가 의문이 든 점이 한 가지가 있었다.
예를 들어 아래와 같이 Offset 방식의 쿼리가 있다고 가정하자.
select id
from employee
order by id
limit 10
offset 10000000;여기서 중요한 점은 Order by 절로 Primary Key인 id만 사용하고 있다.
그래서 든 의문은 이런 것이다. '어차피 클러스터링 키(PK)로 정렬되어 있으니까 그냥 10,000,000번째 데이터부터 읽으면 되는거 아니야?'
즉, 내가 기대한 결과를 그림으로 표현하면 아래와 같다.

만약 과정이 위와 같다면, 해당 상황에서는 Offset 방식이 최초 count 쿼리를 수행한다는 점을 제외하고는 No Offset보다 더 빠를 수도 있지 않을까? 하는 생각이었다.
그래서 간단히 성능 테스트를 해봤다. 먼저 No Offset 방식이다.
select id
from employee
where id > 10000000
order by id
limit 10;
결과 23ms가 수행됨을 알 수 있다. (상당히 빠르다)

실행 계획은 위와 같다.
이제 위에서 작성한 Offset 쿼리를 실행해보았다.
select id
from employee
order by id
limit 10
offset 10000000;
결과는 14s 669ms으로 No Offset과는 비교도 안될 정도로 느렸다.

왜 MySQL은 Offset이 1,000,000일 때 해당 데이터로 바로 접근하지 못하고 1,000,000 번째 이전의 데이터를 또 읽어야 할까..?
그 이유는 MySQL의 데이터는 MySQL이 트리형 자료구조를 가지기 때문이다.
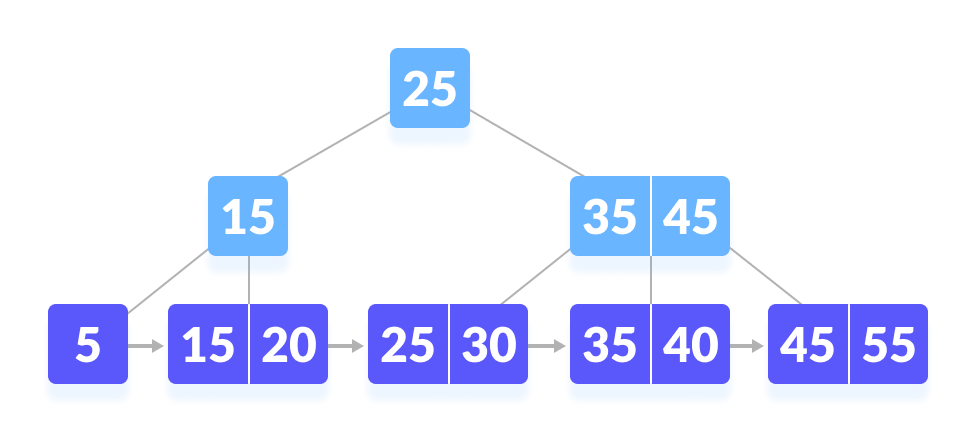
MySQL은 B+Tree 알고리즘을 사용해서 데이터를 조회한다. 즉, Offset이 1,000,000이라고 해도 해당 번째 데이터로 바로 접근할 수 없다. 리프 노드로 가서 순차적으로 탐색해야만 한다.
(인덱스를 단순한 배열이라고 잘못 생각하면서 오류를 범한 것이었다!)
MySQL은 조건문이나 커버링 인덱스 사용 여부와 관계 없이, Offset 방식으로 조회하면 해당 이전의 데이터를 계속해서 추가로 조회를 할 수밖에 없다. 이를 방지하려면 No Offset 방식을 사용해야 한다.
참고
'Database > SQL' 카테고리의 다른 글
| Real MySQL - 파티션이란 무엇인가?! (0) | 2022.06.29 |
|---|---|
| Database - 인덱스 알고리즘 정리! (0) | 2022.06.26 |
| Real MySQL - BETWEEN문 튜닝하는 방법! (with MySQL Server 8.0) (0) | 2022.06.26 |
| Database - 트랜잭션의 특징 (ACID) (0) | 2022.06.25 |
| MySQL - 커버링 인덱스 (0) | 2022.05.31 |