최근에 정보 공유를 하는 곳에서 Redis에 대한 얘기를 많이 들었다.
- Redis를 광적(?)으로 선호하고 만세를 외치시는 분들이 정말 정말 많다!
- 사기템, 만세, 짱짱, 충성, ...
Redis에 대해 이렇게 얘기하시는 분들도 많은 것 같다.
- 조금 큰 규모의 회사라면 대부분 Redis 터지면 서비스가 다 죽을 것이다.
- Redis가 없으면 문닫을 회사도 많다(?)
뭔가 이야기를 듣다보니깐 내가 잘 모르고 있구나.. 라는 것을 느꼈다. (공감이 안됨.. ㅠ)
그래서 Redis에 대해 더 자세히 알아보자.
Cxxpang Redis 사태
2019년 7월 24일에 쿠팡의 모든 판매 상품 재고가 '0'으로 표시되어 주문 및 구매를 할 수 없는 큰 장애가 일어난다.
사유는 해당 시스템이 Redis DB를 통해 데이터를 불러오는 과정에서 버그가 발생했다고 설명했다.
Redis는 Remote Dictionary Server의 약자이며 직역하면 외부에 있는 Key-Value 값의 자료구조(Dictionary)를 저장하는 서버 정도로 해석할 수 있다.
(참고로 Redis는 Value에 대한 자료구조를 매우 다양하게 지원한다.)
- String
- List
- Set
- ...
쿠팡 사태는 해당 Key-Value 형태에서 Key의 개수가 int의 범위를 넘어가면서 문제가 생긴 것이었다. 그래서 Redis 4.0.7에서 해당 이슈를 파악하고 Key Index 값을 int에서 long 타입으로 수정했다.
static int _dictKeyIndex(dict *ht, const void *key, unsigned int hash, dictEntry **existing);static long _dictKeyIndex(dict *ht, const void *key, unsigned uint64_t hash, dictEntry **existing);이제 Redis가 DB라는 것도 알고 Dictionary라는 자료구조를 사용하는 것도 알았다.
Key-value store
Redis는 Key-Value 구조를 사용함으로써 아래의 특징을 가진다.
장점
- 구현이 쉽고 사용이 간편하다.
- Hash를 이용해서 값을 바로 읽으므로 속도가 매우 빠르다.
- RDB의 Index와 같은 개념이 없으므로 데이터 용량이 비교적 작다.
- 분산 환경에서의 수평적 확장성이 뛰어나다.
단점
- Key를 통해서만 값을 읽을 수 있다.
- 범위 검색이나 복잡한 질의가 불가능하다.
1차 저장소와 2차 저장소
1차 저장소
Redis는 저장할 데이터가 정말로 휘발성인 경우에 1차 저장소로 사용할 수 있다. 단, 이 경우 정전(?) 등이 발생하면 저장된 데이터가 모두 날아갈 수 있으므로 유실을 방지하기 위해선 백업 처리가 필요하다.
Redis는 백업을 위해 RDB, AOF 두 가지 방식을 지원한다.
- RDB - 데이터에 대한 Checkpoint로서 주기적인 백업을 하는 방식이다.
- AOF - 쓰기 연산을 할 때마다 내용을 기록하는 방식이다.
Redis는 서버가 재시작할 때 위 방식에 따라 RDB/AOF 파일을 불러와서 복구를 수행한다.
- 아래에서 살짝 언급할 Naver의 nBase-ARC와 같이 백업 방식을 응용해서 Redis를 1차 저장소로 활용하는 사례도 있다.
2차 저장소
Redis는 In-memory Data Structure Store 방식으로 메모리 안에 데이터를 저장해서 사용한다. 즉, Disk I/O가 아니라 메모리 I/O가 발생한다. 그래서 높은 처리 속도를 가지기 때문에 MySQL 같은 DB를 1차 저장소로 사용하고 Redis를 캐시를 용도로 하는 2차 저장소로 사용할 수 있다.
즉, Redis는 나중의 요청에 대한 결과를 미리 저장했다가 빠르게 사용하는 Cache의 목적으로 주로 사용한다.
In-memory가 왜 처리 속도가 빠른지는 Memory Hierarchy 관련해서 찾아보길 바란다. 해당 포스팅에서는 생략 한다.
In-memory 저장 공간을 사용할 때의 특징을 간략 하게만 소개하면 아래와 같다.
- 적당히 빠르다. -> CPU Cache, Register와 비교했을 때 느리지만, HDD나 SSD와는 비교도 안될만큼 빠르다.
- 적당히 크다.
- 휘발성이다.
SpringBoot 앱 서버에서 Redis를 Cache로 사용하는 방법에 대해서는 아래의 글을 참고하면 될 것 같다. (간단하다)
Why Remote?
그렇다면 Remote In-memory DB가 꼭 필요할까?
private final Map<String, Object> cache = new HashMap<>();이렇게 해시맵을 구현해 데이터베이스로 사용해도 메모리 데이터베이스이다. 이렇게 사용했을 때 문제는 뭘까?!
문제 1. Consistency(일관성)의 문제가 발생한다. 즉, 서버가 여러 대일 경우 각 서버가 보관하는 데이터가 다를 수 있게 된다.
문제 2. Application에 장애가 나거나 새 버전을 배포하면 데이터가 모두 유실되는 문제가 있다.
문제 3. Race Condition이 발생할 수 있다. 여러 개의 쓰레드에서 하나의 Map을 사용하면서 동시성 문제가 생긴다.
이러한 문제 때문에 Redis와 같이 애플리케이션 외부의 원격(Remote) 저장소가 필요한 것이다.
Redis에서는 Race Condition 문제 때문에 아래의 해결 방법을 채택하고 있다.
- 기본적으로 Single Threaded로 동작한다.
- 사실은 메인 쓰레드 1개와 별도의 시스템 명령을 사용하는 Sub Thread 3개가 존재하지만, 실제로 처리에 사용되는 쓰레드는 메인 쓰레드 1개라고 이해하면 될 것이다.
- 추가로 Atomic Critical Section에 대한 동기화를 제공한다.
- 그래서 각 Transaction이 Read/Write를 동기화하면서 원치 않는 결과를 얻는 것을 방지한다.
Write Back
로그와 같이 단순한 데이터를 DB에 Write 해야하는 경우 매번 Write를 수행하면 상당히 부담스럽게 된다. (Write는 일반적으로 Read보다 느리고 비용이 많이 발생한다.)
이때 Redis를 사용해서 Write Back 방식으로 문제를 해결할 수 있다.

Write Back은 Insert할 데이터를 Cache에 모으고 일정한 주기 또는 일정한 크기가 되면 한번에 Insert할 때 유용하다.
Local cache, Global cache, pub/sub
현재 아래의 3가지를 기능을 모두 사용하는 개발 팀이 많다.
- Local cache
- Redis cache(Global cache)
- Redis pub/sub을 통해 변경된 내용에 대해 모든 사용자에게 전파
Local cache와 Redis cache의 차이를 비교해보자.
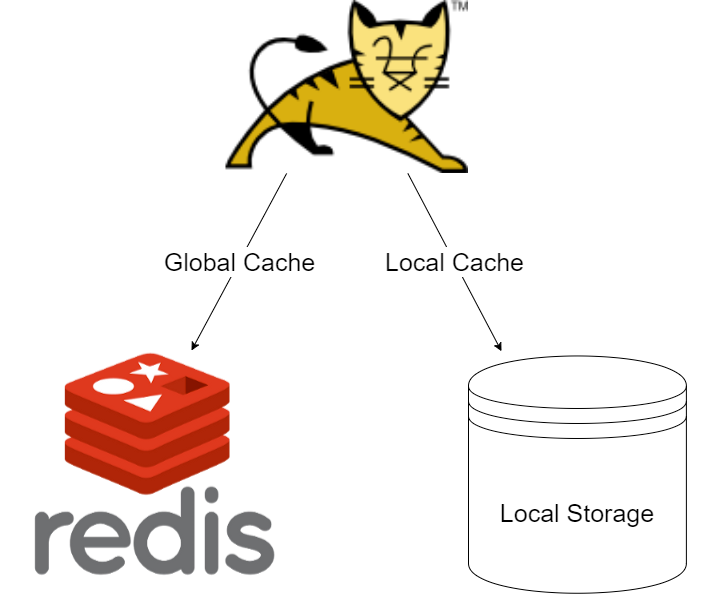
Local Cache
- 데이터 조회 오버헤드가 없다.
- 처리 속도가 빠르다.
- 서버마다 캐시를 따로 저장한다.
- 서버간 동기화가 어렵고, 동기화 비용이 발생한다.
Redis(Global) Cache
- 네트워크 I/O 비용이 추가로 발생한다. (Redis에 접근하는 비용)
- 데이터 일관성을 유지할 수 있다.
Local Cache와 Global(Redis) Cache의 특징을 고려했을 때 어떤 기술을 선택할지에 대한 기준은 '데이터 일관성이 깨져도 비즈니스에 영향을 주지 않는가?'가 된다.
물론 Local Cache와 Global Cache 양쪽 다 사용할 수도 있다.
Redis pub/sub
Redis의 pub/sub는 주로 채팅 기능이나 푸시 알림 등에 사용되는 기능이다.
Redis pub/sub은 해당 채널에 구독 신청을 한 모든 Subscriber에게 메시지를 전달한다.
Redis pub/sub은 Kafka와 비교했을 때 더 빠르다는 장점이 있다.
그러나 Kafka와 다르게 Redis Channel은 메시지를 '던지는' 방식으로 동작하기 때문에 메시지를 보관하지 않는다. Subscribe 대상이 하나도 없는 상황에서 메시지를 publish한다면 해당 메시지는 사라지게 된다는 점을 유의해야 한다.
즉, 비용은 아끼고 성능이 좋지만 신뢰성이 중요하거나, 로그 메시지 통합 등 유연한 재처리하기 위해서는 다소 부적절할 수 있다.
Redis pub/sub을 사용하면 변경된 내용을 전파한 뒤 다른 서버(subscriber)에 저장하는 등의 시스템을 구현할 수 있다.
- 앱 서버에서 변경된 내용을 Redis pub/sub의 Subscriber에게 전파
- Subscriber는 자신이 사용하는 캐시를 갱신
Replication
Redis는 휘발성을 가지고 있는 메모리 상의 데이터이다.
그래서 항상 데이터가 유실될 문제를 고려하고 있어야 한다. 그래서 Redis는 데이터 복제(Replication) 기능을 지원한다.
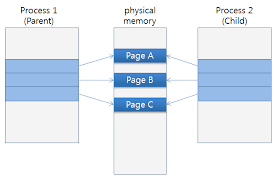
이때 만약 메모리가 가득 차있다면 복사본이 메모리에 제대로 생성되지 않고 앱이 죽기 때문에 메모리를 반드시 여유있게 사용해야 한다.
Cluster
추가로 Redis의 메모리는 제한되어 있기 때문에 주기적으로 Scale out, Back up을 해야 한다.
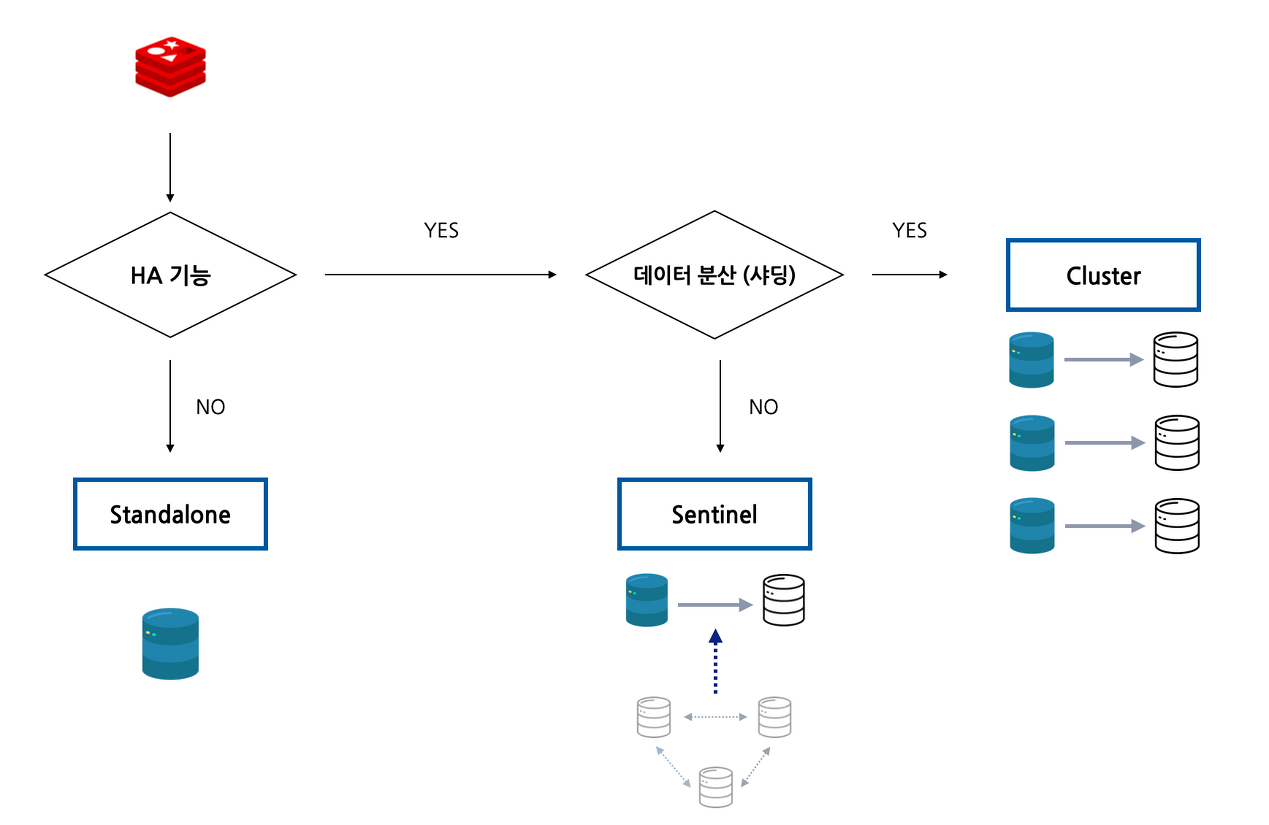
Redis의 운영모드는 세 가지가 있다.
- Standalone - 하나의 레디스 서버만 운영하는 모드
- Sentinel - Master 노드가 강제 종료되면 Slave 하나가 승격하는 모드
- Cluster - 데이터를 분산해서 처리하는 모드
Redis Cluster
Cluster 모드는 Range, Modular, Hash, Indexed 등의 기법으로 데이터가 저장될 노드를 결정한다.
추가로 노드 하나에 장애가 발생하거나 서버가 증가되면 기존 노드에 적재된 데이터들이 리밸런싱된다.
스프링부트에서는 아래의 설정으로 간단하게 Redis cluster를 구성할 수 있다.
spring:
redis:
cluster:
nodes:
- 10.123.1.88:6400
- 10.123.1.88:6401
- 10.123.1.88:6402나는 Redis가 NoSQL이므로 Redis Cluster가 그렇게 안전한 것과는 거리가 있을 것으로 생각했다.
그런데 Naver D2에서 본 내용이나 기술 공유 등을 통해 레디스가 정말 튼튼하다고 믿게 되었다.
- Naver에서는 nBase-ARC라는 Redis Cluster를 자체로 제작하여 메인 DB로써 활용하기까지 한다.
- 해당 링크에는 nBase-ARC의 내부 구현이 잘 정리되어 있다! 정말 너무 재밌다(https://d2.naver.com/helloworld/614607)
주의할 점
Redis는 단순한 get/set이라면 초당 10만 TPS 이상이 가능할 정도로 빠르다.
하지만, 앞에서 언급했듯 Redis는 Single Thread 서버이므로 명령의 시간 복잡도를 고려해야 한다.
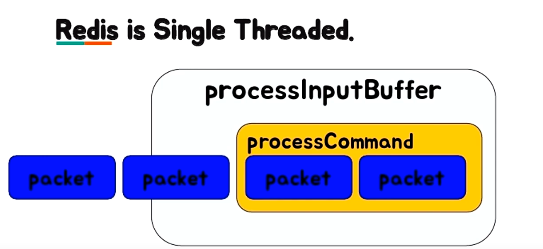
즉, 만약 processCommand가 O(N)이 수행되는 Keys, Flush, Get all과 같은 명령이라면 뒤의 요청들이 병목이 발생할 수 있다.
추가로 In-memory DB 특성 메모리 파편화, 가상 메모리 등의 이해가 필요하다.
참고
'Database > NoSQL' 카테고리의 다른 글
| NoSQL - MongoDB는 대용량 데이터를 처리하는 Database일까? (0) | 2023.03.16 |
|---|---|
| ElasticSearch 이해하기! (0) | 2023.02.23 |
| 레디스 데이터 타입 정리! (0) | 2022.12.29 |
| MongoDB란 무엇인가?! (기본 이해하기!) (0) | 2022.12.28 |
| In-memory DB 비교 (Redis vs Memcached) (0) | 2022.07.10 |