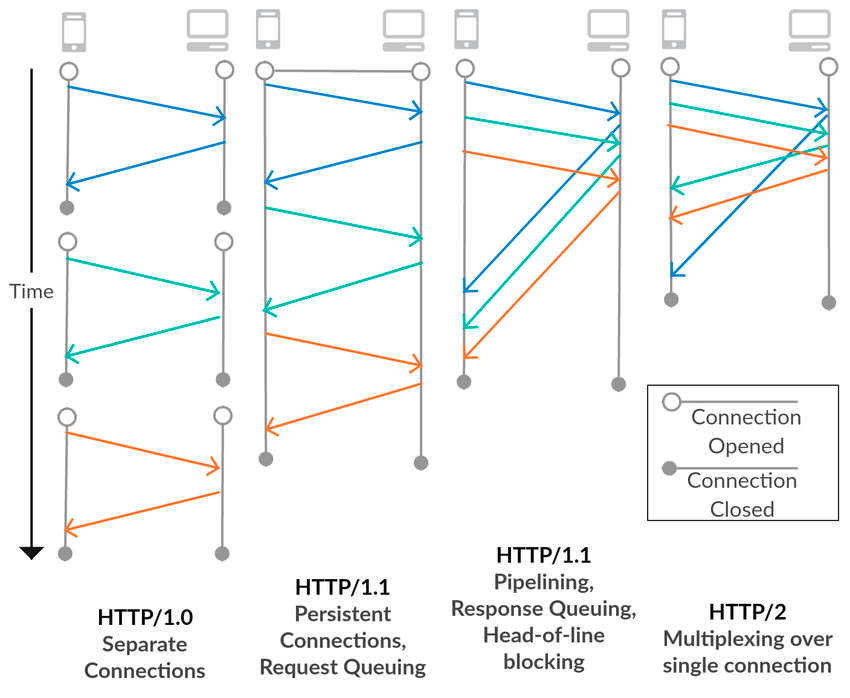
HTTP 1.1 버전은 15년 동안 지속되었습니다. 하지만 하나의 웹사이트에 무수한 리소스가 존재하고 무수한 요청을 주고 받게 되면서 HTTP 1.1이 가진 문제점이 대두되면서 HTTP 2.0이 등장했습니다. HTTP 1.1과 HTTP 2.0의 차이점을 HTTP 1.1(기존)의 문제점과 HTTP 2.0의 해결 전략을 중심으로 알아보겠습니다. Multiplexed Streams HTTP 1.0에서 TCP 세션을 맺는 것을 중복해서 수행하는 성능 이슈가 있었고, HTTP 1.1에서 Keep-alive를 통해서 해당 문제를 풀어냈었습니다. https://jaehoney.tistory.com/279 HTTP 2.0에서는 Multiplexed라는 기술을 도입하는데 1개의 세션으로 여러 개의 요청을 순서 상관없이 ..